Research
I am primarily interested in problems at the intersection of multimodality, commonsense abilities, and reasoning. My broad goal, in future, is to work towards unified architectures capable of modelling efficient and semantically convergent representations of different modalities corresponding to human sense-perception, to design and evaluate systems that enable the emergence of commonsense abilities in large models akin to humans, and to enable sound, verifiable, and scalable reasoning in foundation models.
Ongoing Work
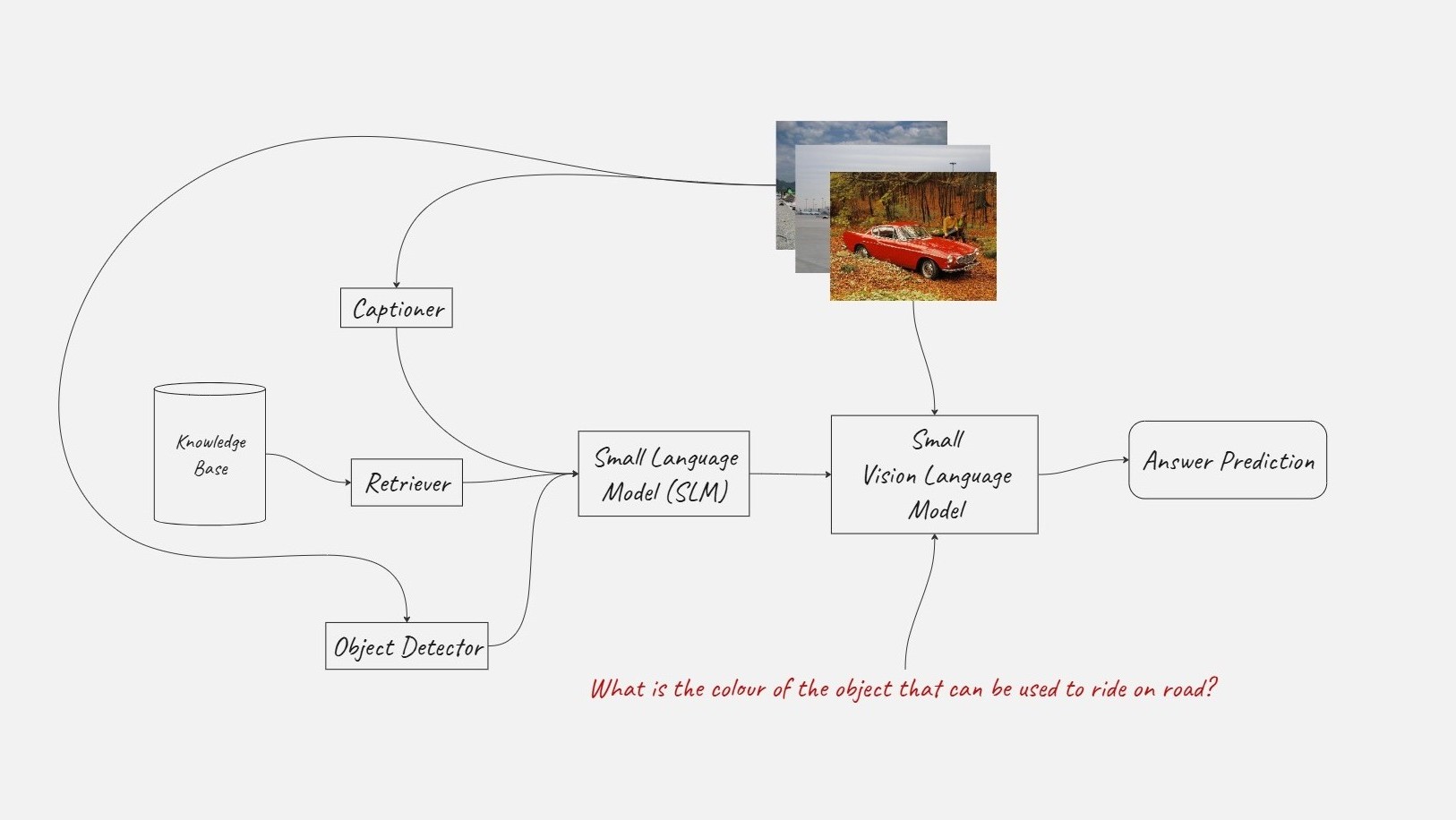
Undergraduate Thesis on Neurosymbolic Reasoning for VQA: I am extending the framework proposed in NELLIE and TV-TREES family of work to enable grounded and verifiable reasoning for Visual Question Answering (VQA). I am primarily working to (a) expand the scope to open-domain commonsense-based VQA, (b) improve the mechanism of visual information integration into the inference engine, (c) use small, local models instead of large closed-source models in the engine.
Modality Bias and Preference in MLLMs: In collaboration with a group at Precog and Tanuja Ganu, Microsoft Research India, we are investigating modality bias and preference in large 'omni' models (MLLMs) which can input and output multiple modalities such as text, image, audio and video. Our preliminary findings reveal that these models exhibit uneven capabilities across modalities, performing non-trivially better in some modalities than others for the same tasks. Currently, we are working to create a benchmark that can quantify this limitation and provide a true measure of multimodal understanding through information composition and counterfactual understanding tasks across multiple modalities.
Past Experience
ML-based Forecasting of Antiretroviral Therapy (ART) Drugs: I worked with Prof. Debayan Gupta and in collaboration with Prof. Steven Clipman of the Johns Hopkins Medicine Institute to develop machine learning methods for enhanced forecasting of various antiretroviral therapy (ART) drug regimens for the National AIDS Control Authority of India (NACO) supported by the GKII Breakthrough Grant 2024. I led the development of the initial prototypes of our method and set up the data ingestion and preparation pipeline in coordinators with various stakeholders at NACO and presented initial results to NACO. We finally settled on using an adaptive model based on a combination of ARIMA and TimesFM which outperformed the existing methods significantly. Our poster on this work was also invited to be presented at the Johns Hopkins GKII India Tour in 2024.
Document Text Recognition for Indic Languages: As an ML Engineer Intern at Sarvam, I independently developed the first prototype of Sarvam's document text recognition pipeline from scratch, supporting over 10 Indic languages. My responsibilities included setting up the full pipeline for data curation, collection, and preparation. I experimented with various end-to-end multimodal architectures, exploring different encoder and decoder models to devise an appropriate modality fusion mechanism and fine-tuning recipe for the task. The entire system was trained end-to-end on large-scale data using a multi-node distributed training cluster framework. Additionally, I contributed to Sarvam's Parsing API through rigorous benchmarking and evaluations prior to its release.
Zero-Shot Coreset Selection: Under Prof. Raghavendra Singh, I worked to develop compute-efficient and easily scalable methods for coreset selection (dataset distillation) through a graph and network-analysis centered approach. I came up with a novel zero-shot method for coreset selection on image datasets using a simple PageRank-based approach for dataset distillation. The key highlight of this technique is its ability to identify important examples in a given dataset without requiring any training on that target data. The method achieves performance comes close to current state-of-the-art (SOTA) methods while being more computationally simple and efficient.
ML-based Cancer Metastasis Prognosis: I contributed to the AISCan project during my first year, which focused on the precision profiling of cancerous tumor cells for a predictive analysis of cancer metastasis and progression. We developed a novel machine learning-based method of digital cytometry to classify and quantify gene expression data from human stem cells. This allows for a highly accurate profiling of tumors to aid in the diagnosis and treatment of the disease. My specific responsibilities included collating and preparing the data used for training, running all ML-based experiments, and developing the primary codebase for a software package that integrates this functionality into a user-friendly tool. This work is currently under review for a publication (see the preprint below!) and a patent.
All Publications
For citation information, please check my Google Scholar.
2025
2023
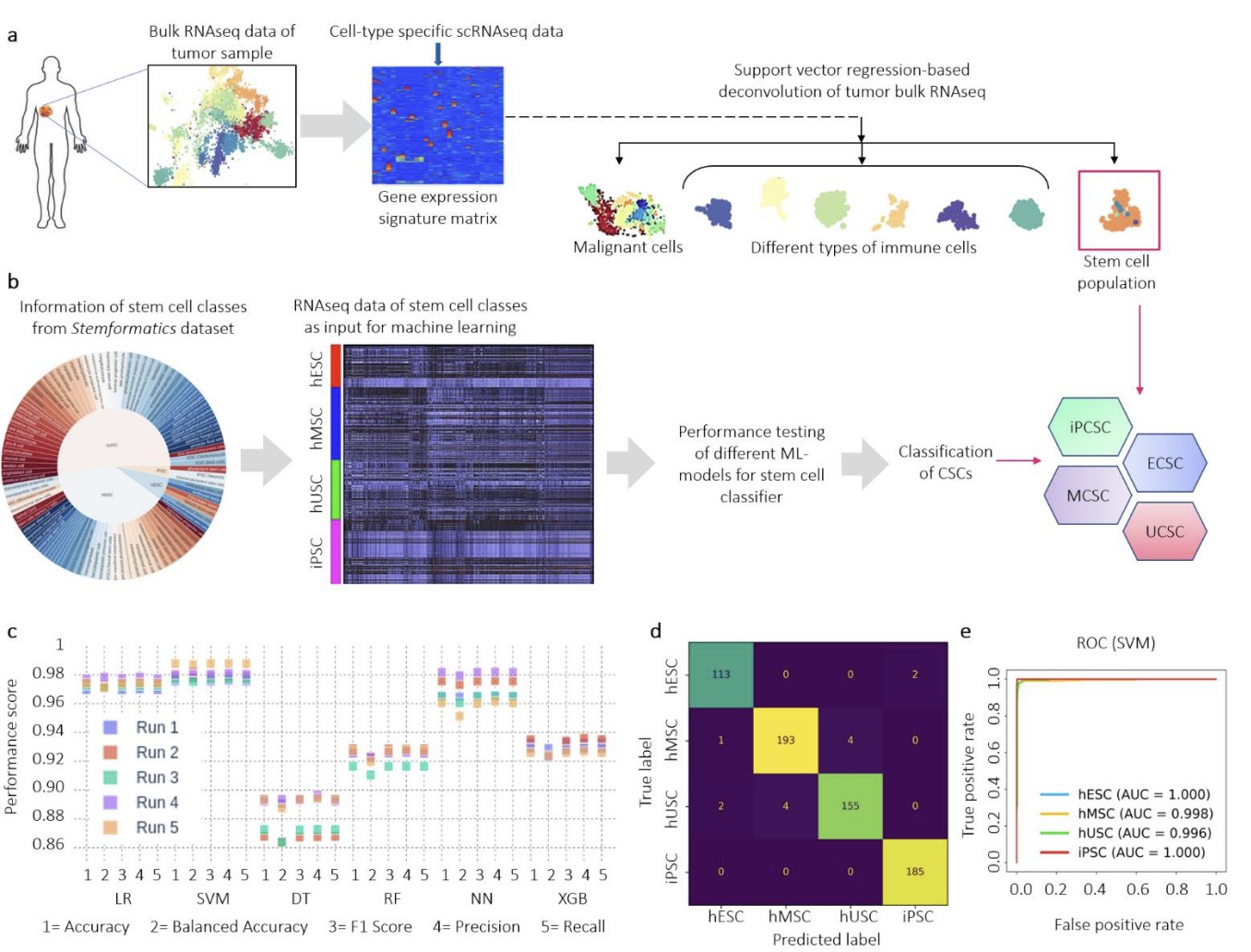
Next-Gen Profiling of Tumor-resident Stem Cells using Machine Learning
![FedTree: Federated Learning on Tabular Medical Data [Poster]](/assets/images/publications/fedtree.jpg)
2021
